- Published on
Enabling automatic "skip-to-next-scene" in videos
- Authors
- Name
- James Brady
- @james_elicit


Don't video player controls seem dumb?
Desktop and web-based players alike allow the user to jump forwards or backwards by 5 or 10 seconds, or possibly speed up and slow down playback. These controls operate identically no matter what the user is watching – there's no connection between the content of the video, and the controls.
DVDs were the first format I know of that allowed you to skip via chapters, but even something as basic as those coarse-grained content-aware controls aren't available in things like YouTube videos today.
Here's an idea for how to identify the salient points in a video that a user might want to skip to: the good news is that this could all be done automatically, and with very little overhead; I'll leave the bad news to the end!
Video compression – how does it work?
The short answer is: I don't know, but that's never stopped me before so…
A key concept in video encoding is frame types. Each frame (a single image in the video) can either be a key frame or an inter frame. Key frames are easy to understand – they are just a picture, stored as something like a JPEG we're all familiar with.
Inter frames are where things get interesting. The idea is that for the vast majority of video content, frame N is pretty similar to frame N-1 (and frame N+1 for that matter). Using this fact, it's possible to store frame N in a much more compact way by representing it as a delta on its neighbouring frames. Interestingly, this so-called inter framing is why colours and shapes can appear to erroneously "smear" over a second or two of video if the video file is damaged or incomplete. The decoder gets confused and can propagate forward corruption from one frame into subsequent frames.

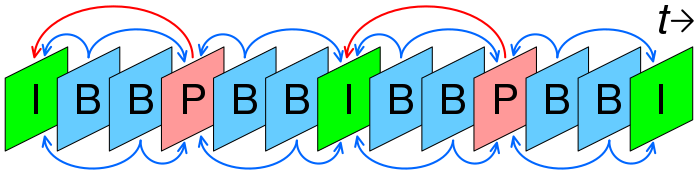
Video encoders support automatic insertion of key frames when they detect a significant delta between two frames – e.g. across scene changes. The thinking here is that if two adjacent frames are quite dissimilar, there's no benefit in calculating delta and using an inter frame: we might as well store the first frame of the new scene as a key frame.
What does this have to do with skipping video?
One consequence of this mix of key frames and inter frames in a video is that we have indicators as to when scene change events are happening. The video encoder is using these events internally, to decide between key or inter frames, but I think they also enable a content-aware skip feature.
When we hit the "skip forward" button, imagine the video jumps ahead to the next key frame – rather than 5 or 10 seconds into the future. If those key frames are aligned with scene changes, you get per-scene skipping basically for free.
Imagine how expensive it would be to have a human manually add cue points to video, demarcating every scene change? For a platform like YouTube – where 400+ hours of video are uploaded every second – this is beyond impossible.
Almost as a side-effect, the video encoding process builds up an understanding of transition points where one frame is very dissimilar to the last – because it wants to insert key frames there. If we save the locations of those key frames as metadata alongside the encoded video, we have everything we need to power a more intelligent skipping feature.
To improve on this, rather than saving just the key frame locations, we could also save the similarity between frames at those points. With that data, the skipping feature could be finer grained (stopping at every single key frame) or coarser grained (only stopping at key frames where a huge delta was detected).
Sounds great, let's do it! Why won't it work?
A couple of reasons:
Sometimes frames change a lot during a single scene
For example, suppose the hero steps out into the sunshine. Or there's a massive explosion. Or somebody turns a bedside light on. The examples go on and on where we – as humans – understand there's a contiguous flow to the content, but our poor old video encoder probably thinks that these two frames have very little to do with each other.
On the other hand, perhaps this isn't such a huge problem: the majority of scenes do consist of gradually changing frames, so although it's easy to come up with counter examples, in the general case it's still workable1.
Most video encoders don't use automatic key frame insertion
This is the real problem. The majority of video that we watch nowadays is a) streamed and b) variable bit rate, and that's not a good fit for auto key framing.
Honestly, I'm not familiar enough with adaptive streaming technology to say why it's dependent upon evenly-spaced key frames, but I can tell by instinct it would make things much more straightforward. There certainly doesn't seem to be an easy way to apply an inter frame at one resolution on top of a key frame at another. For that reason, ensuring that the various steams' key frames are in sync – so we can switch between streams at key frame boundaries – seems like a great choice. The even-spacing: I'm not so sure why that is important…
Perhaps at some point in the future, dependence on evenly-spaced, in-sync key frames will go away, and we can revisit using the key frame spacing to power user features like this, rather than just as an internal video encoding detail!
Footnotes
One interesting point here: what about scenes where the camera is panning? From one frame to another, there could be quite low pixel-by-pixel similarity as everything is shifting left to right. Luckily, modern video encoding also has all sorts of incredibly clever object tracking functionality, so objects moving across the screen – or even the whole shot panning – can be represented in a way which still appears to be a small delta. ↩