- Published on
Synaesthetic music visualisation with CycleGANs
- Authors
- Name
- James Brady
- @james_elicit


About a decade ago, a friend and I were talking over dinner about our shared passion for electronic music. Our burning question was: how can we convince the world to love techno as much as we do?
A common – and not always unfair – criticism is that electronic music can be repetitive, lacking an overall arc, or overly simplistic: especially when compared to something like a classical concerto. However, your appreciation of concertos greatly deepens once you understand the three movement structure, repeating motifs, question and answer, and all the other tricks and conventions present in classical music: we thought the same rule applied to electronic music.
In order to demonstrate the macro-structure and texture of the music, our idea was to pair the audio with illustrative visualisations.
VJs (who produce video and light shows to complement a DJ's set) were already quite popular, but the interconnection between the DJ's audio and VJ's visuals was tenuous at best… Perhaps a good VJ would match the mood and rhythm of their show to the music in real-time, but they weren't able to reify a deeper structure in the musical performance1.
At its worst, the visualisations were just endless jankily-looped clips of Muybridge's horse films to give the gurners something to gurn at.
The goal
These visualisations would need to reveal the patterns already present in the music. They would need to have a cohesive style to them – to ensure internal consistency bar-to-bar – but they would also need to be modulated by the music in an intuitive way. For example, perhaps spikier shapes for distorted sounds, or different colours for different tones and instruments, different size shapes for greater or lesser volumes, ...
We wanted a system which could dynamically generate this imagery in real time, even for live performances.
Starting small
To start off with something relatively simple, I first focussed on transforming short, single-note audio clips into small hand-drawn "squiggles".
 A simple, smooth, sine wave... ... might map to something like this
A simple, smooth, sine wave... ... might map to something like this A more complex sound... ... would result in a busier shape
A more complex sound... ... would result in a busier shapeI applied a machine learning technique known as CycleGANs to attempt this mapping from audio to illustrative figures.
What is a CycleGAN?
Although it's possible to build a conventional AI system2 capable of this audio-to-video mapping, I chose to use CycleGANs instead.
Generative Adversarial Networks (GANs) are a pair machine learning networks where the networks have opposite goals. One network is called the generator: its goal is to create realistic fakes – images, video, or audio for example. In contrast, the discriminator network is trying not be be fooled by the generator's forgeries. The generator is rewarded when the discriminator judges its output to be authentic; the discriminator is rewarded when it correctly spots a forgery, and when it correctly identifies an authentic example.

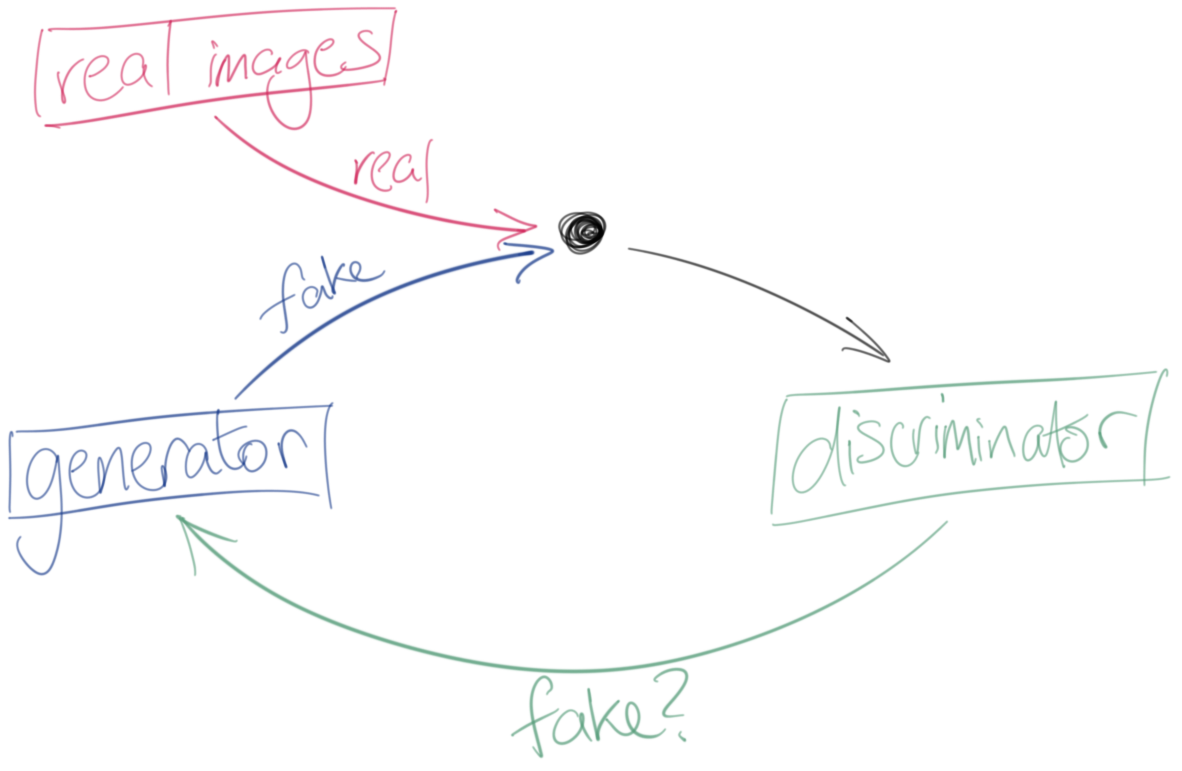
There are many applications of GANs. The best known is probably Deepfake videos that can do things like turn Donald Trump into a sassy local news reporter. One of their key benefits is that they tend to require less human feedback to become effective, because the generator and discriminator networks effectively train each other. Another benefit is that they can exhibit creative behaviour: the selection pressure exerted by each network on the other can result in strategies that humans would be unlikely to find alone.
Building on the idea of GANs, CycleGANs arrange two GANs into a loop. Rather than having a single pair of networks with opposite goals, we now have two pairs of networks. The first pair is expert at creating fakes in one domain (for example, forged photographs of horses). The second pair is expert in another domain (for example, forged photographs of zebras).

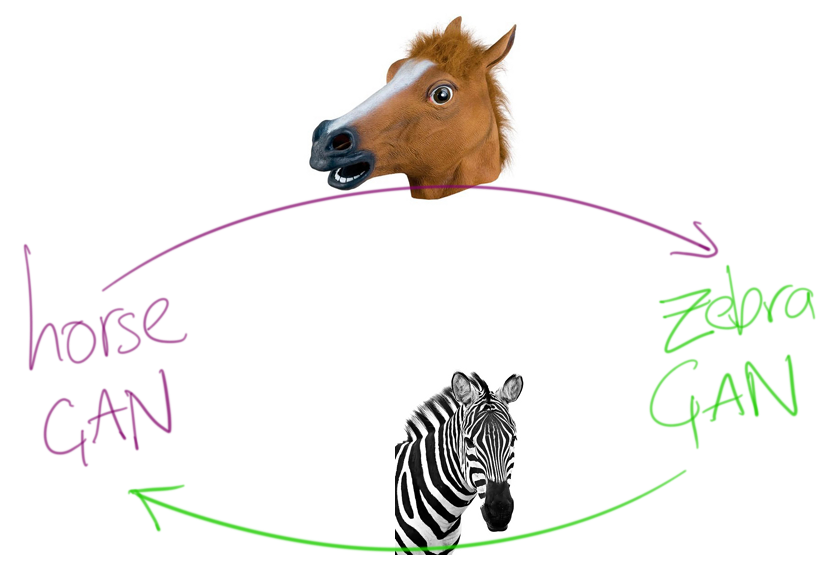
By hooking up the inputs, outputs, and training processes of all of these networks, they can be trained as an overall composite system – in a similar way to how a single GAN combines two networks.
In the following diagrams, the notation is:
- is a generator which takes zebra images as input, and produces horse images as output
- is a discriminator for horse images
- is a generator which takes horse images as input, and produces zebra images as output
- is a discriminator for zebra images
- real horses and real zebras are training data made up of authentic photos of the corresponding animals
If the discriminator is perfect, it correctly identifies authentic photos from the training data.
We can use the generators to create fake images. A perfect discriminator would spot these forgeries.
In addition to the GANs becoming more able to create and spot forgeries, CycleGANs train the networks to increase cyclic accuracy3. What this means is that not only should each GAN's output be realistic, but when we do a full pass through the GANs' interconnected inputs and outputs, the final result should be as close as possible to the original input:
When we map from a real zebra to a generated horse, and from that generated horse to a generated zebra, we want to end up with an image identical to the initial real zebra.
CycleGANs have been shown to be effective at a variety of tasks, including animal transformations (e.g. horses to zebras), season transformations (e.g. summer scenes to winter, stylistic transfer (e.g. photograph to Monet).
I wondered if I could use them to achieve a much more ambitious transformation: from sound to image.
Synaesthetic music visualisations
As far as I know, CycleGANs have only been used to map between dimensionally similar domains before: images to images, audio to audio, etc. However, for this application I needed to be able to convert two-channel, 1-dimensional data (audio) to three-channel, 2-dimensional data (images). For this first version, I took the quick and easy approach of simply reshaping the data, something like this:
# Reshaping audio into an image
# This is the first step in our image generator model
audio_shape = (43264, 2)
in_audio = keras.models.Input(shape=audio_shape)
axis_size = int(math.sqrt(audio_shape[0]))
reshaped = keras.layers.Reshape((axis_size, axis_size, 2))(in_audio)
# Reshaping an image into audio
# This is the last step in our audio generator model
number_of_audio_samples = image_shape[0] ** 2
out_audio = keras.layers.Reshape((number_of_audio_samples, 2))(model)
The rest of the networks were unchanged from the original CycleGAN paper4, apart from a couple of dimensionality tweaks in the network architecture to accommodate mixing and matching audio and visual data.
The results
Overall, the results are surprisingly effective for a quick first attempt!
- The training data was 1024 hand-drawn squiggles, and 256 sound clips made with the Helm synthesier
- I used a
p2.xlargespot instance in AWS (terraform config adapted from Vithursan Thangarasa) - The system was trained for 15 epochs (the original paper called for much more training than this – 100s of epochs – but I found the audio-to-image training significantly slower than training horse-to-zebra networks)
Here's how we did:
Clean, simple, sine sounds



More complex, modulated sounds
The audio recreated from the visualisation is still a pretty close match

This one looks really similar to the one above, and the audio is very similar too

These visualisations have a lot more going on than for the simpler sounds. Does anyone else see the face?
Lower frequencies, smoother envelopes
With lower frequencies and broader sounds, the visualisations seem more spread.



Even with this naïve approach, some synaesthetic transfer is discernable:
- Time effectively moves vertically, from top to bottom: sound clips where the note is later in the window map to images with the pattern lower down. I view this more as an artefact of reshaping the data rather than a salient transfer, however.
- Notes with a slower attack, sustain, decay envelope result in a more diffuse, broader, lighter stroke.
- Sounds with a more complex timbre (noise, resonant frequencies, distortion, …) result in shapes with more internal texture.
Next steps
Fourier to the rescue
My expectation is that the current weakest link is the naïve munging of the outputs to get data shaped like audio or image. Instead of this simplistic approach, using a Fourier transform to generate 2D output from audio seems a good idea.
Non-raster outputs
For this particular output domain (the hand-drawn "squiggles" mentioned above), having the system output in SVG rather than raster format would be interesting to try. The visualisations would gain a natural cohesion, but it's not immediately clear how to ensure the output is valid SVG... It would likely need to output an AST-like structure from which we could generate actual SVG.
Other training data
As mentioned in a footnote2, building this system with conventional supervised machine learning would take a lot of time. To retrain the system for different types of sounds or different visualisation styles would require a human to create a corpus of audio-image pairs. However, with this system we could feed unicode alphabets, the works of Miró, photographs of sunsets, or any other image data into the CycleGAN without any human supervision: the networks would need to be retrained, but this takes just a few hours and costs a few dollars.
Polyphony
Even with some of the improvements mentioned above, how would this work for real music, when there there are tens of voices and instruments all sounding in parallel, in a continuous fashion? The prototype outlined here is only capable of working with 1-second monophonic snippets.
A couple of thoughts here:
- To handle continuous audio, we could use a sliding window to bucket the audio stream into discrete, overlapping chunks (this would work well with the Fourier transform). The overlapping nature of these samples would tend to smooth out the visualisation too.
- For polyphony, although it's possible that a larger network could figure out how to discern individual tracks within a larger piece, I suspect a better approach would be to hook directly into a tool like Ableton Live so that we can visualise each track separately, and only then combine them into a cohesive whole.
Google have Magenta Studio which hooks directly into Ableton Live as a new breed of AI-powered synthesiser, but rather than appearing as a tool to the producer, we would be shuttling the output of a performance to our CycleGAN for the VJ to use.
Footnotes
Hamill Industries' recent work with Floating Points shows how far we've come since 2008. The video for Anasickmodular is the closest proxy I can find to a live performance we saw at MIRA in 2019 where they (a) modulated the oscilloscope-style with the sound in real-time, then (b) modulated the oscilloscope line to show a lo-fi CRT-style representation of a video feed of Floating Points on stage 🤯. I realise this description makes no sense, I've been trying to wrap my head around what I saw and how to explain it for 18 months now. ↩
A conventional approach would probably use supervised machine learning. However, the training process would be extremely time-consuming for the human supervisor: I would effectively have to say "when you hear something like this, you should draw something like that". As an estimate, it would take tens of thousands of such audio-video pairs to train the AI to even a basic level. CycleGANs don't suffer from this time-consuming need for paired training examples. ↩ ↩2
The original CycleGAN work (and most of the later variants I've found) also aims to preserve identity accuracy, meaning that if we pass a generator some input from its output domain, it tends to output the input unchanged. In more concrete terms, if a horse-to-zebra generator is given a picture of a zebra, it should ideally return the unchanged picture of the zebra. ↩
I used this guide which implemented a slightly-simplified version of the CycleGAN in Keras. ↩