- Published on
Alignment windfalls are a robust way to avert AI disaster
- Authors
- Name
- James Brady
- @james_elicit


Tl;dr
- Most approaches to AI alignment incur upfront costs to the creator (an “alignment tax”).
- In expectation, startups will skimp on alignment in order to avoid the tax.
- “Alignment windfalls” are strategies which tend towards long-term public good and short-term benefits to a company.
- One suggestion for a high impact career is to discover, validate, and advocate for these alignment windfalls so as to accelerate their adoption.
Reasons to pay alignment taxes
Before I champion alignment windfalls, let's first define alignment taxes and explore why companies might be willing to pay them.
An “alignment tax" refers to the reduced performance, increased expense, or elongated timeline required to develop and deploy an aligned system compared to a merely useful one. Happily, there are several reasons why companies might accept these costs. Here are some examples:
Regulation
Causes like environmental protection or consumer safety made progress when governments decreed that companies must absorb additional costs in order to protect the public: from pollution and unsafe products respectively1. Regulation meant it was a smart economic decision for these companies to better align to the needs of the public.
Regulation is fast becoming a reason to pay some alignment tax for AI too. For example, red-teaming will soon become required for companies building foundation models due to the Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence.
Marketing
Regulation is often used to set a minimum standard that companies must meet on prosocial measures, but marketing strategies can push beyond this and incentivise excellence. For decades, Volvo built immense brand equity around the safety features in their cars with adverts demonstrating how crumple zones, airbags, and side impact protection would protect you and your family.
In AI, the marketing dynamic remains centred around avoiding PR disasters, rather than aiming for brand differentiation. Infamously, Alphabet briefly lost $100 billion of value after its splashy launch adverts included a factual error. Hopefully, AI companies “do a Volvo" and compete on safety in the future, but there probably isn't enough public awareness of the issues for this to make sense yet.
Recruiting
Given two similar employment choices, most candidates would favour the option which better aligns with their own moral code. Good examples of this will be found at mission-driven non-profit organisations, staffed by team members who could often find much better-compensated work at for-profit orgs, but who find significant value in aiding causes they believe in.
As for AI, the competition for talent is extraordinarily competitive (yes, we're hiring). Panglossian AI optimists might not care about the safety stance of the organisation they work at, but most would pay some heed. Therefore, AI companies which prioritise alignment—even if it comes with a tax—can boost their ability to hire the best people and remain competitive.
Incentives to avoid alignment taxes
In some cases and in some industries, the above reasons are strong enough to align company behaviour to the public good.
Unfortunately, I don't think they're powerful enough when it comes to AI.
Although the “Reasons to pay alignment taxes” points above do apply to AI startups, they’re not absolute. The upside for organisations leading the AGI race is gigantic, so there is incredible countervailing pressure on anything standing in the way: alignment taxes start to look a lot like inefficiencies to be eliminated.
Startups as optimisers
Startup companies are the best machines we've invented to create economic value through technological efficiency.
Two drivers behind why startups create such an outsized economic impact2:
- Lots of shots on goal. The vast majority of startups fail: perhaps 90% die completely and only 1.5% get to a solid outcome. As a sector, startups take a scattergun approach: each individual company is likely doomed, but the outsized upside for the lucky few means that many optimists are still willing to give it a go.
- Risk-taking behaviour. Startups thrive in legal and normative grey areas, where larger companies are constrained by their brand reputation, partnerships, or lack of appetite for regulatory risk.
In this way, the startup sector is effectively performing a directed search operation over our legal and normative landscape. They're looking for the most efficient way to create value, and they're willing to take risks to do so.
Emergent harmful behaviour
But what about the staff at these organisations? Wouldn't they put their foot down when asked to compromise on their values and race towards something dangerous?
The literature suggests not. Ethical, well-meaning people can and do behave in unethical ways when complex group interactions are at play.
- Umphress (2011) suggests that loyalty to an organisation can lead to unethical behaviour, with one mechanism being “neutralisation": a process of rationalising the behaviour as being for the greater good.
- Pearsall (2011) found that a utilitarian bent increases the chances of unethical behaviour, whereas a more deontological approach decreases it.
- Thau (2015) identifies social exclusion as a driver for pro-group unethical behaviour.
None of the above points are aimed at any specific organisation. In particular, I hold the leading AI labs in high regard, and know that people inside those companies are aware of the pitfalls and are actively working to avoid them.
However, that's not enough: not by a long shot.
AGI will be the most valuable thing we've ever created. Depending on your perspective, it could be the most important thing we'll ever create; it could even be the most important thing ever created in our light cone.
We don't just need today's leading AI labs to be aligned (although we do need that). We need every significant AI organisation now and in the future to be properly aligned, across all countries, with all kinds of founding charters, all while algorithmic and hardware capabilities continue to improve exponentially. Yikes.
So what's the solution?
This all sounds terrible so far… but I think there is a way forward!
There are some ideas and some businesses where progress on AI safety is intrinsically linked to value creation. Companies which aren't creating powerful AI and also working to make it safe; rather, companies making progress on AI safety because it makes their AI more valuable.
This might seem like a distinction without a difference, but I don't think so. When push comes to shove in a venture-backed startup (and push always comes to shove), non-essential functions are the first to get cut: meaning that alignment work is at risk of being deprioritised.
When progress on a company's core value driver is inseparable from progress on safety, however, there won't be such a stark choice between them.
What we need is to discover and promote these alignment windfalls.
Cool story bro
Are there any actual examples of this? It sounds too good to be true.
Well, I think there are a couple and—spoiler alert—I think Elicit is the best. (Yes, we're hiring).
Interpretability
Interpretability (meaning our ability to introspect and understand the workings of a neural network) is widely held to be a key component of AI safety (e.g. 1, 2, 3, …). It can help spot inner misalignment, deception, aid with design and debugging, and lots more.
Companies founded on productising interpretability are incentivised to make their tools' output as truthful as possible. This is value creation for the business3.
Reinforcement learning from human feedback
RLHF is one of our most effective alignment tools at the moment. Notwithstanding the concerns that it's just putting a friendly face on a monster…

… it's clearly the case that RLHF can make models safe-r. Nathan Labenz was one of the volunteers who assessed an early, “purely helpful" version of GPT-4, and found it was “totally amoral", suggesting targeted assassination as the best way to slow down AI progress4. It's not known exactly what OpenAI did to improve GPT-4 before its public release, but we do know RLHF was a part of it.
Anthropic suggested that an aligned ML system should be helpful, honest, and harmless. RLHF is our best mechanism for making Pareto improvements on these three axes. RLHF-ed models can be more valuable and safer.
Factored Cognition
Factored cognition is a term we coined for an alternative paradigm for AI systems.
Since the deep learning revolution, most5 progress on AI capability has been due to some combination of:
- More data.
- More compute.
- More parameters.
Normally, we do all three at the same time. We have basically thrown more and more raw material at the models, then poked them (with RLHF) until it seems sufficiently difficult to get them to be obviously dangerous. This is an inherently fragile scheme, and there are strong incentives to cut corners on the “make it safe" phase.
Factored cognition offers a different path.
Instead of solving harder problems with bigger and bigger models, we decompose the problem into a set of smaller, more tractable problems. Each of these smaller problems is solved independently and their solutions combined to produce a final result. In cases where factored cognition isn't great for generating a result, we can factor a verification process instead.
The Elicit AI research assistant uses factored cognition: we decompose common research tasks into a sequence of steps, using gold standard processes like systematic reviews as a guide.
For our users, accuracy is absolutely crucial. They are pinning their reputation on the claims that they make, and therefore something which just “sounds plausible" is nowhere near good enough. We need to earn their trust through solid epistemic foundations.
For Elicit, creating a valuable product is the same thing as building a truthful, transparent system. We don't have some people building an AI tool and also some people figuring out how to make it reliable. Trustworthiness is our value proposition.
Isn’t this just increasing capabilities?
No, alignment windfalls don’t just increase capabilities.
They do engender highly-capable AI systems, but in forms that we believe are safer for some principled reason. If you believe we have to stop, pause, or radically decelerate AI progress in order to stay safe, then alignment windfalls are probably not your cup of tea.
If—like me—you think it’s unlikely or undesirable that we uproot the market dynamics which have shaped our policies and society for centuries, then it would be wise to use those dynamics in our favour: this is what alignment windfalls aim to do.
For-profit as a feature
Eric Ho has an excellent list of for-profit AI alignment ideas. My thinking diverges from his slightly, in that the main benefit he sees is the ability to scale faster with VC money:
With VC dollars, a for-profit organization can potentially scale far more quickly than a non-profit. It could make a huge impact and not have its growth capped by donor generosity.
I agree, but would go a step further. The ideas Eric lists are generally ancillary tooling around AI systems, rather than the systems themselves. In this way, they don’t hook directly into the inner loop of market-driven value creation, and might have a smaller impact as a result.
Won’t startups just do this anyway?
Earlier, I suggested that in aggregate, startups are searching for the most efficient way to create economic value with technology. If these alignment windfalls truly exist, why wouldn’t we simply expect for them to be discovered and exploited by any old company rather than one which prioritises AI safety?
Well, there are two main problems with that story.
- Myopia. Startups tend to run on tight feedback loops. Using quick, iterative release schedules they excel at pivoting to whatever direction seems most promising for the next month or two. They tend to make lots of local decisions, rather than grand strategies. This isn’t to say that startups are unable to make bold moves, but in my experience the vast majority of decisions at the vast majority of startups are incremental improvements and additions to what’s already working.
- Secrecy. If a startup did happen to find an alignment windfall, they would be incentivised to keep it secret for as long as possible. Thankfully, this dynamic is generally not true for AI companies where there is still a norm of publishing research about interesting new techniques; this seems like an unstable equilibrium though.
It follows that the organisations best-suited to surface and popularise alignment windfalls would have:
- A lot of latitude to explore ideas which haven’t yet been proven viable.
- The ability to publish and promote these ideas, when they have been found and proven.
Non-profit organisations and public benefit corporations are natural fits for this kind of thing. It doesn’t seem impossible for conventional for-profit organisations to do this too, but certainly more challenging given how the fiduciary duties of the officers might be interpreted.
Conclusion
Most AI labs seem to be careful and deliberative actors, but as more competitors enter the race for AGI the pressure to avoid any and all hindrances will increase. Future competitors may well be less cautious and even explicitly reject hindrance: e/acc types already have their own AI labs.
If this is the world we're heading towards, AI safety measures which impose significant alignment taxes are at risk of being avoided. Instead, we should discover and promote alignment windfalls, by which I mean mechanisms that harness the awesome efficiency of markets to create aligned AI systems.
I'm a proponent of other approaches—such as regulation—to guide us towards safe AI, but in high stakes situations like this my mind turns to the Swiss cheese model used to reduce clinical accidents. We shouldn't hope for a panacea, which probably doesn't exist in any case. We need many, independent layers of defence each with their strengths and (hopefully non-overlapping) weaknesses.
In my view, Elicit is the best example of an alignment windfall that we have today. To have maximum impact, we need to show that factored cognition is a powerful approach for building high-stakes ML systems. Elicit will be a compelling existence proof: an example which we hope other people will copy out of their own self-interest. We are looking for the best possible team to make this happen and if this post resonated with you, you should check our open roles.
Footnotes
This locally-applied imposition can lead to much better outcomes overall. Freeman (2002) shows that the impact of environmental regulation wasn't limited to qualitative improvements like restored waterways: there were also significant quantitative economic benefits mostly stemming from direct improvements to human health. ↩
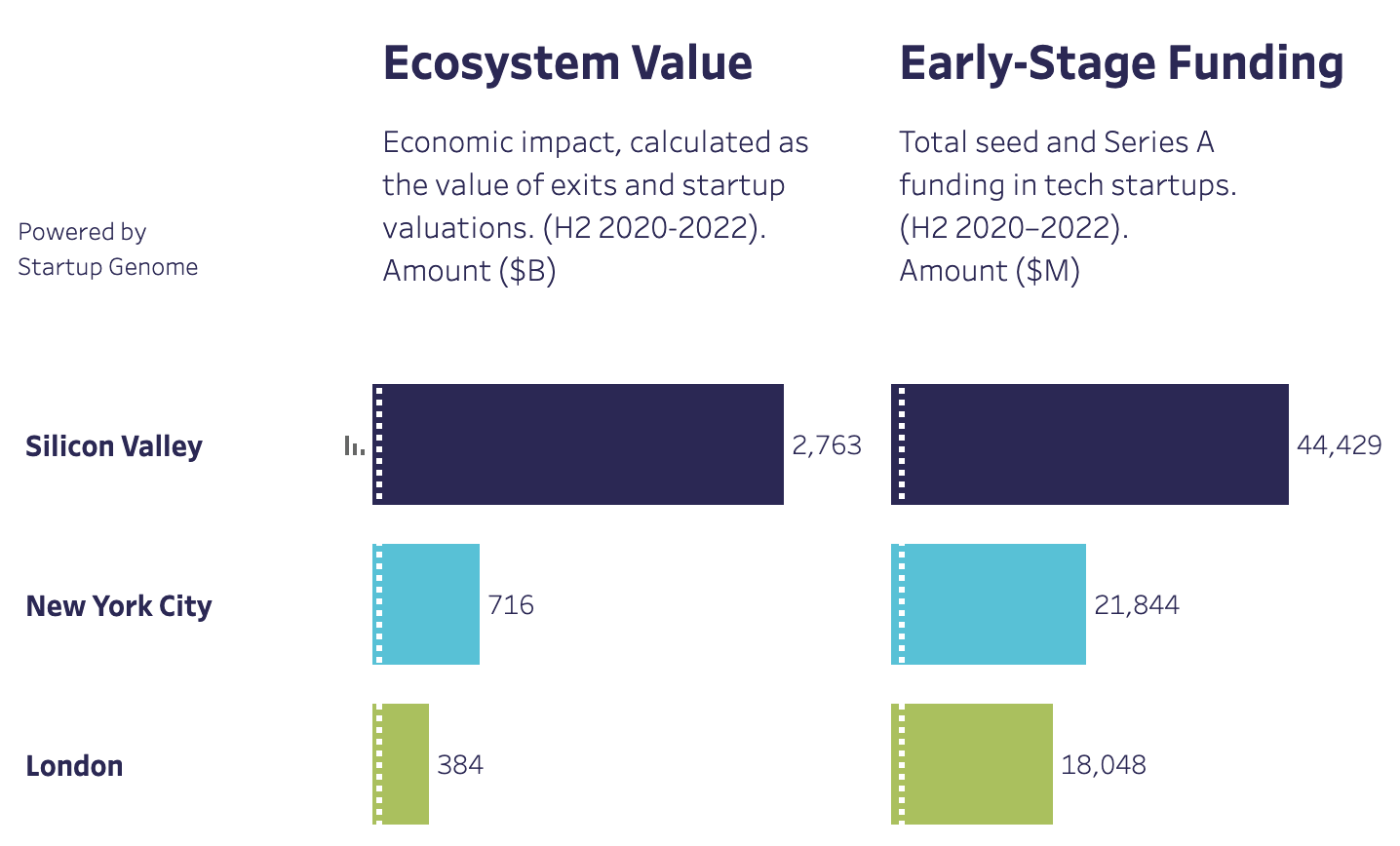
According to Startup Genome, there was a 50x return on seed and Series A funding from 2020–2022:
↩Some have noted that interpretability could be harmful if our increased understanding of the internals of neural networks leads to capability gains. Mechanistic interpretability would give us a tight feedback loop with which to better direct our search for algorithmic and training setup improvements.
Also, if a startup is following a “interpretability as a service" path, they are to some degree incentivised to give their customers the answers they want to hear. ↩
Nathan is an investor in Elicit. Did I mention we're hiring? ↩
… but certainly not all. For example, AlphaGo used tree search alongside several task-specific neural networks, rather than just brute scale. There have been breakthroughs on prompting and architecture too. ↩