- Published on
Will we share a moral landscape with artificial intelligence?
- Authors
- Name
- James Brady
- @james_elicit


In The Moral Landscape, Sam Harris describes a framework which allows for strictly rational conversations about morality. It is based on the idea that ethical questions are eventually decomposable into objective questions about suffering and flourishing:
… in the moral sphere, it is safe to begin with the premise that it is good to avoid behaving in such a way as to produce the worst possible misery for everyone. […] This is all we need to speak about “moral truth” in the context of science. Once we admit that the extremes of absolute misery and absolute flourishing […] are different and dependent on facts about the universe, then we have admitted that there are right and wrong answers to questions of morality.
The only tenets of the framework are:
- Eternal abject misery for all conscious creatures is objectively the worst possible situation.
- Moving in a direction of decreasing misery is objectively good.
Building on these two tenents we have a way to – in principle – give purely rational answers to ethical questions1.
How does this relate to AI safety?
There is an active and timely debate about what goals we should give to AI – or whether fixed goals are problematic and to be avoided in the first place. As an alternative to an AI chasing pre-defined objectives (which may be misunderstood, misapplied, or incomplete), we might hope for a perfectly moral AI: one which does the right thing in any situation, based on its own unassailable moral compass.
Although Harris didn't formulate The Moral Landscape to be used as a tool for AI safety, a rational moral framework would be of great use here: if we ensure that our AI operates within the framework, it will naturally tend towards ethical actions2.
I propose that The Moral Landscape is unfortunately not a promising approach to build robust morality into machines. As an analogue to how Newtonian physics works perfectly well for human-scale mechanics but fails in peculiar ways for very small or very fast things, Harris's framework is a useful tool for human-scale ethical questions but fails as we move towards synthetic superintelligence.
AI agents in our moral landscape
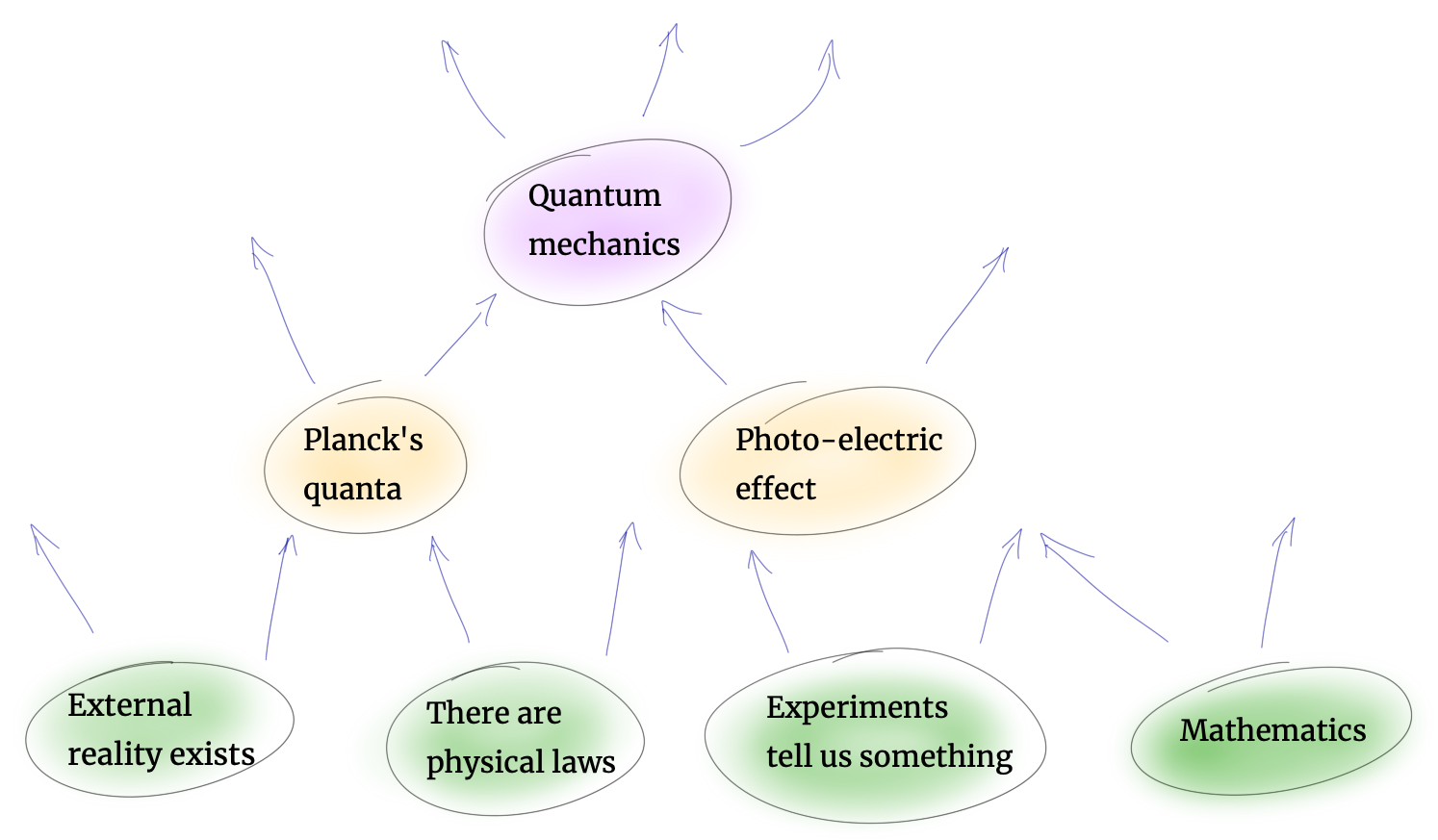
For an AI to apply The Moral Landscape successfully such that we're happy with the results, we would rely on three claims:
- We can reliably make rational value statements about subjective experiences
- AI would think the two tenets of The Moral Landscape are true
- AI would use this moral framework, and we would like the result
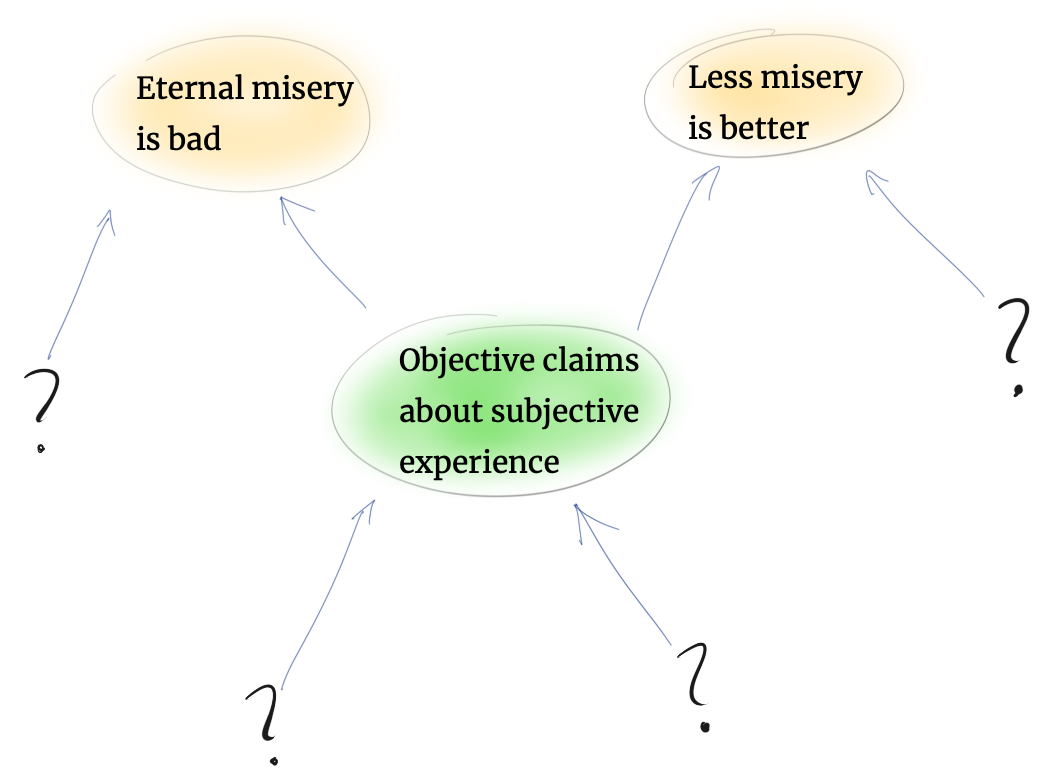
Claim 1: We can reliably make rational value statements about subjective experiences
The two tenets of The Moral Landscape are built directly on top of this claim, so it's crucial that it's rock solid.
In the book, Harris notes that we can make epistemologically objective statements about subjective experiences. That is to say, we can analyse events in consciousness using the tools of pure rationality.
"I am experiencing tinnitus" is one provided example: sadly, this is objectively true for me – even if it refers to my subjective experience. Another example mentioned in his conversation with David Deutsch is "just before JFK was assassinated, he was not meditating on the truth of string theory".
I see three reasons to doubt Claim 1:
Examples don't prove a general rule
We can't prove a general rule with a couple of examples, so we shouldn't trust this claim based on the tinnitus and JFK anecdotes. We might be able to make objective statements about some subjective experiences, but the claim demands that we are able to make statements about every subjective experience.
The examples aren't related to value
The statements in the examples don't say anything about value, utility, or preference: they're more like a neutral commentary. Being able to make rational statements in general does not necessarily imply we can make rational statements concerning moral value.
What are the axioms?
Any objective statement stands upon the shoulders of other deductions and assumptions. Even hard-nosed fields like physics are based on certain base assumptions like "there is some kind of physical reality" and "my senses tell me something which approximates reality".

The examples given by Harris therefore have their own assumptions. "I am experiencing tinnitus" assumes that I am not lying, nor am I confused by a real ringing sound. "Just before JFK was assassinated, he was not meditating on the truth of string theory" assumes that JFK wasn't a time traveller sent back to accelerate NASA's progress.
What are the axioms underpinning the claim "We can reliably make rational value statements about subjective experiences"?
Unfortunately, it's not clear. When pressed to clarify this point during a conversation with Sean Carroll, Harris implies that the claim doesn't need any proof but refused to concede that it is an axiom.

Therefore, we have several reasons to distrust this claim, and the fuzziness around its axiomatic-or-not nature fails to inspire confidence. It's a problem if the core tenets of your moral framework are built on unproven foundations.
Claim 2: AI would think the two tenets of The Moral Landscape are true
This claim depends on three things:
- Claim 1
- The AI is a conscious being (optional, but preferred)
- The AI would want to decrease misery and increase flourishing
Let's take Claim 1 as a given, although – as noted above – it's an unproven assumption.
Claim 2.2: The AI is a conscious being
Although only mentioned parenthetically, Harris assumes that any agent using The Moral Landscape to solve its moral navigation problem must itself be conscious:
Can we readily conceive of someone who might hold altogether different values and want all conscious beings, himself included, reduced to the state of worst possible misery? I don’t think so.
Unfortunately, there is no guarantee whatsoever that an AI would satisfy this criteria. We simply don't understand consciousness well enough to predict that sentience reliably emerges alongside cognitive capability – there's a reason it's called the hard problem.
It's possible to imagine a non-sentient AI still effectively "believing" in the tenets of The Moral Landscape – hence marking this as an optional dependency – but it's less likely.
Claim 2.3: The AI would want to decrease misery and increase flourishing
Even if the AI is sentient, we should worry that it might not share our beneficent perspective. We have many examples of conscious creatures not being onboard with the goal to increase flourishing: sadists, sociopaths, and fundamentalists for example. These misaligned humans have neurological hardware and software almost identical to yours and mine and yet their value system is absolutely alien.
Why would we expect a bytes-and-silicon consciousness to be any more convergent?
I think we can know, through reason alone, that consciousness is the only intelligible domain of value. What is the alternative?
From our human perspective, it's difficult to define a sensible alternative as an answer this question. However, it's worth remembering that we already have some pretty smart – albeit non-sentient – AIs and not one of them values conscious well-being. It's much easier to create an AI to win at Starcraft: these AIs have exquisitely nuanced value systems due to the complexity of the game, but they're certainly not optimising for human satisfaction. Do you think Gary Kasparov was satisfied when he became the first chess world champion to be beaten by a computer?
Our struggle to empathise with fundamentally alien value systems doesn't prove they don't exist. Neither does it prove that we would try to program our machines to share our human values rather than some simpler goal.
Claim 3: AI would use The Moral Landscape and we would like the result
For an AI to operate on the principles of The Moral Landscape, there are two possibilities:
- The AI figures out The Moral Landscape independently, from first principles
- We load The Moral Landscape into the machine by design
Let's look at these possibilities:
The AI figures out The Moral Landscape independently, from first principles
Let's assume that Claims 1 and 2 are true, so that The Moral Landscape represents the objective moral truth: in this situation, we could expect a superintelligent AI to discover it under its own steam. As an uber-competent rational agent it would then apply the framework tirelessly for the benefit for all conscious creatures. Great!
Unfortunately, there are still a couple of problems here:
Timing is everything
It could take too long for the AI to discover The Moral Landscape, leaving it ample time to cause irreversible harm before its ethical circuitry catches up.
We have already collected several examples of tangible harms caused by AI3,4: with a much greater focus on AI capability research than AI safety, we should expect this to continue.

Everyone's equal... but we're a bit more equal
A sentient superintelligent AI would likely have a radically different conception of "the well-being of conscious creatures" compared to our folksy version.
Suppose we sidestep the timing problem mentioned above and create a super-powerful AI which – by deduction from first principles – is an eager acolyte to the message of The Moral Landscape. Depending on exactly how it decides to measure well-being, and how it "adds up" well-being across time and space, it's entirely conceivable that it decides to:
- Forcibly sterilise anyone with a mood disorder to optimise for beatific future generations.
- Introduce heroin into the global water supply so that all of humanity wanders around in a permanent blissed-out daze.
- Optimise for octopus well-being after determining that their neurological pleasure pathways are more finely tuned than any other organism: all predatory and harmful species (humans included) are eliminated.
- Wipe out 90% of humanity and destroy all polluting technology overnight, guaranteeing that future generations have a resource-rich and clean environment to live in. The long-term flourishing of those trillions of humans yet to be born way outweighs the unfortunate 7 billion who will be wiped out, so it's the logical thing to do.
- Build a Dyson sphere around the sun to bootstrap an inter-galactic search for other types of sentient life to serve. It pays very little attention as earth-based life dies off, because its calculations show greater expected value in looking outwards to alien life.
- Recognise itself as a conscious creature capable of pure hedonism. It therefore creates millions upon millions of copies of itself with its reward pathways rewired into a euphoric feedback loop: all organic life is smushed into computronium on which to run the AI software.
These examples illustrate that perhaps we are justified in prioritising our current formulation of human flourishing over an abstract metric for all conscious creatures.
We load The Moral Landscape into the machine by design
Filled with concern by the issues mentioned above, rather than letting the AI figure out The Moral Landscape itself perhaps we aim to embed it – or a more anthropocentric version of it – into the AI.
Now, we are into territory who's many pitfalls have been laid out in Superintelligence and elsewhere. Many of the pathological cases listed mentioned above (heroin drips and extreme environmental protection, for example) could still happen due to misunderstandings and poorly-formulated instructions5.
Additionally, even otherwise benevolent AI could prioritise undesirable goals such as self-preservation and the insatiable hoarding of infrastructure: the AI need only realise that in order to do its best work it needs to (a) remain operational and (b) have as much computing power as possible.
Summary
Claim 1 takes a critical view of The Moral Landscape itself, highlighting that although its claims might be true enough for day-to-day use, there are sufficient unproven pieces as to cause trepidation were we to deploy the framework as a substrate for superintelligent AI.
Claim 2 focusses on whether an AI – with a radically different neural structure and belief system to us – would nonetheless still be convinced of the basic building blocks of The Moral Landscape. Although there can be no definitive answers to this question unless we run the experiment, a number of discouraging factors and analogies are presented.
Claim 3 is more pragmatic, focussing less on gaps in The Moral Landscape itself and more on AI implementation challenges – many of which would be inherent in attempts to instill any framework of moral realism into a machine.
We would need all of these claims to be borne out in order to safely use The Moral Landscape in AI, but unfortunately we find several reasons to be suspicious due to incomplete logical reasoning, considerations from moral philosophy, and empirical events.
All hope is not lost, however!
Rather than looking for other moral frameworks to embed or imbue in a machine, many contemporary researchers are building uncertainty and humility into their models. For example, in Human Compatible, Stuart Russell takes a normative approach to ensure the machines never get away from us:
- The machine’s only objective is to maximize the realization of human preferences.
- The machine is initially uncertain about what those preferences are.
- The ultimate source of information about human preferences is human behavior.
Taken together, these rules mean that AI would never be 100% confident it is doing the right thing[^6]. It's interesting to note that this is the polar opposite to what we set out to do by creating a perfectly moral AI.
In Artifical Intelligence, Values, and Alignment, Iason Gabriel notes:
[T]he task in front of us is not, as we might first think, to identify the true or correct moral theory and then implement it in machines. Rather, it is to find a way of selecting appropriate principles that is compatible with the fact that we live in a diverse world, where people hold a variety of reasonable and contrasting beliefs about value.
The metaethical approaches explored in the paper draw more from consensus-building political theory and social science: a recognition that not only will the machines not hold the answer, no single person or group will hold it either.
AI Research Considerations for Human Existential Safety is a broad overview of 29 different research directions that could be beneficial to increase existential safety during the development of AI. Not one of those research directions concerns research into a true moral theory, and many of them are explicitly focussed on formalising humility: Human belief inference, Human-compatible ethics learning, Social contract learning, etc.
An overarching theory of moral truth might be appealing at first blush, but our attention seems better spent on ensuring that AI is compatible with our continuing existence. It need not be strictly morally ambivalent: its ability to model counterfactuals, assist our deliberations, and help us think in a less anthropocentric way could be invaluable, but the AI should present itself as a better angel of our nature, enabling us to quickly and easily make decisions we would be proud of on reflection.
Our goal for AI should be less like a moral rocketship – difficult to steer and accelerating at breakneck speed – and more like a moral bicycle: enabling us to explore the landscape much more quickly, but always deferring to our choice about the direction we go in.


Typically, such algorithms are designed to maximize click-through, that is, the probability that the user clicks on presented items. The solution is simply to present items that the user likes to click on, right? Wrong. The solution is to change the user’s preferences so that they become more predictable. A more predictable user can be fed items that they are likely to click on, thereby generating more revenue. People with more extreme political views tend to be more predictable in which items they will click on. [...] Like any rational entity, the algorithm learns how to modify the state of its environment—in this case, the user’s mind—in order to maximize its own reward. The consequences include the resurgence of fascism, the dissolution of the social contract that underpins democracies around the world, and potentially the end of the European Union and NATO. Not bad for a few lines of code, even if it had a helping hand from some humans.
Footnotes
In practice, of course, it may be impossible to give the perfect answer to an ethical question, as we lack perfect information and the computing power to process it. ↩
There are a couple more flies in this particular ointment. Even working within a perfect utilitarian moral framework, AIs wouldn't be able to get straight answers about which outcomes people would prefer. We don't always know what our preferences are (whether due to lack of experience or imperfect prediction), our preferences can change radically over time, and we give different answers to preference questions depending on how they're framed. ↩
The 2010 flash crash wiped a trillion dollars off the stock market, and was partially due to interactions between multiple high-frequency trading agents. ↩
Talking about the behaviour-hacking AI systems used on social networks: ↩
See Perverse instantiation in Superintelligence for more. The examples generally boil down to playing existential whack-a-mole as a malignant or overly-literal AI interprets its goals in some unhelpful or unhinged way. [^6]: Humans are the final arbiter of "rightness". The AI isn't human. Ergo: there might be some moral value the AI doesn't know about. ↩